随着业务和功能的不断迭代更新, App的安装包大小也在不断的增加. 初期或者特定功能的App或许不明显, 但是如果你想要你的App获得更好的用户体验, 那么缩减App安装包的体积是你不得不考虑的一部分. App安装包的大小直接或间接地影响着下载转化率,安装时间,磁盘空间等重要指标. 根据谷歌商店的内部数据,APK体积每减少10M,平均可增加1.6%的下载转化率.
换句话说, 你的App安装包每多6Mb, 你的用户增长就会减少1%. 而这个比例, 或者说App安装包的大小, 在新兴市场中受到的影响更大. ^1
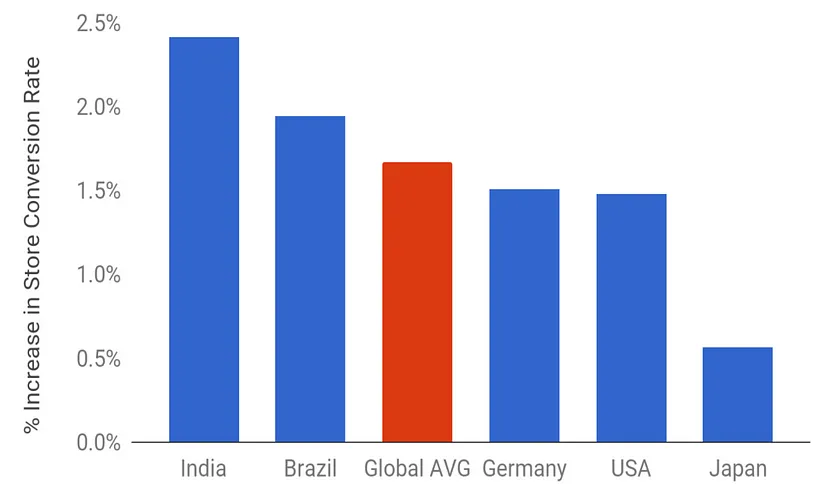
当然, 即使没有详尽的数据说明, 我们也能明确的感受到App安装包的大小对我们应用的影响.
那么, 我们又改如何缩减我们的App安装包大小呢?
我们先来看一下Google官方推荐的方法: Reduce your app size
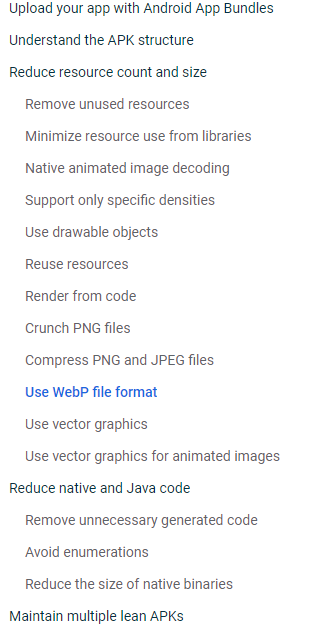
首推的方法就是使用App Bundles, 而App Bundles的主要功能就是在应用安装时自动选择对应分辨率下资源文件, 来达到最低成本减少应用大小的目的.
而关于减少App安装包大小的部分,我们可以看到大部分的篇幅都是关于如何通过处理资源文件来达到我们的诉求.
我们再来看一个App安装包大小的分析, 我们可以看到一个10Mb左右的应用, 其资源文件可以达到6.1Mb.

虽然其中不全是图片资源, 但是图片资源再其中占比仍能达到九成以上. 那么压缩图片资源就是一件性价比很高的事情了.这也就成为了我们开始处理App安装包大小的时候所做的第一步. 也是最明显的一步.
而Google也早就帮我们在AndroidStudio集成了一个高性价比和简单便捷的工具WebP.Use WebP file format
每次使用WebP都是那么的简单和便捷. 不知道你有没有考虑过, WebP是如何影响Android应用的大小? 或者说WebP是如何做到在不影响显示效果的前提下, 减少图片的大小?
图片格式相关概念
在具体分析WebP压缩功能之前, 我们需要了解一些基础的图片格式相关的概念. 以便帮助我们了解后续比较.
RGB/YUV/YCbCr
RGB
RGB是我们通过模拟的三原色(红Red, 绿Green, 蓝Blue)而形成的(最终混合为白色). 标准的RGB模式为RGB24, 分别是8位R,8位G,8位B表示. 如果加上A(Alpha), 就形成了我们在开发过程中常使用的颜色标识方法RGBA. 这个标准下共需要32(8*4)位来存储.
YUV
YUV则是通过电视的发展而不断改进形成的, 早起的电视都是以黑白为主,也就是说我们只需要记录亮度Y(Luminance)即可. 而随着彩色电视的发展, 单纯的亮度Y不足以满足彩色的需求, 于是变有了色度U(Chrominance)和浓度V(Chroma).
YCbCr
YCbCr是YUV的一种变种, 它是为数字视频转换而设计的非绝对颜色模型(绝对颜色模型是指不依赖任何外部因素就可以准确表示颜色的模型). 和YUV一样, Y表示的是亮度(Luminance), 而Cb代表的是RGB 输入信号蓝色部分与亮度之间的差值也叫蓝色色度(Chroma Blue), Cr代表的是红色部分与亮度之间的差值也叫红色色度(Chroma Red).
RGB/YUV/YCbCr实际分离效果
| RGB^2 | YUV^3 | YCbCr^4 |
|---|---|---|
 |
 |
 |
当然, 他们直接是可以互相转换的.RGb<->YCbCr: http://licheng.sakura.ne.jp/hatena6/rgbyc.html
索引色/ 直接色
索引色
索引色是通过一个索引表来表示颜色的. 也就是说, 我们只能通过对应的索引来记录有限的颜色信息.
直接色
直接色则是通过直接记录颜色信息来表示颜色的. 也就是说, 我们可以通过直接记录颜色信息来记录足量的颜色信息. 比如我们常用的RGB24, 其就是直接色的一种.
位图/ 矢量图
位图
位图就是我们常说的点阵图或者像素图. 简单来说, 构成位图的最小单位是像素, 假设我们有一个10*10像素的位图, 那么我们就有100个像素点的信息. 因为其特性, 位图在放大的时候会出现锯齿, 也就是我们常说的马赛克.
矢量图
矢量图也被称为向量图. 矢量图是通过数学公式来描述图像的. 也就是说, 矢量图是通过一系列的点来描述图像的. 由于其特性, 矢量图在放大的时候不会出现锯齿. 但是矢量图也有其局限性, 由于其是通过数学公式来描述图像的, 所以矢量图只能描述一些简单的图形, 而不能描述复杂的图形.

我们可以看到, 即使在高放大的情况下, 矢量图仍可保证其显示效果.
有损/无损压缩
无损压缩
无损压缩就是在压缩的过程中, 不会丢失任何信息. 也就是说, 无损压缩的图像在解压缩后和原图像是完全一致的. 其压缩的主要原理是相同的颜色信息只保存一次. 从本质上来说, 无损压缩通过删除重复的内容的方法来达到压缩图片大小的目的. 但是当图片读取的时候, 软件又会把压缩的数据(删除的重复内容)重新计算出来, 所以其占用的内存大小和压缩前的图片是一致的. 也因其特性, 所以不论你压缩/解压多少次, 压缩后的图片大小解压后的显示效果都是不变的.
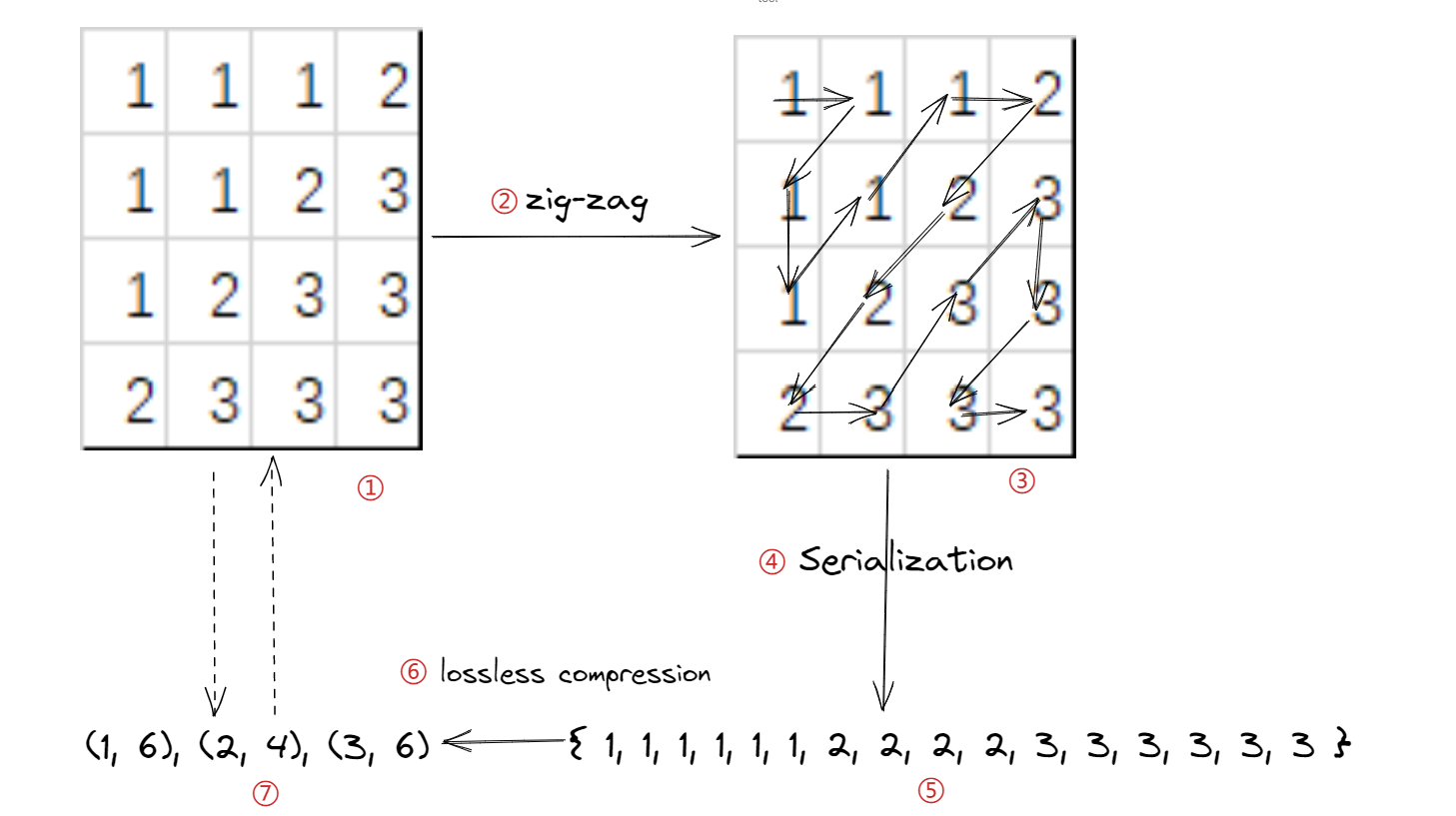
假设我们有如下①的4*4像素的内容, 其中每个像素点的颜色都是不同的, 那么我们就需要记录16个像素点的颜色信息. 我通过②③④,zig-zag序列化将其转化为⑤{1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3}, 也就是我们的原始数据, 如果不压缩那么我们就需要记录这16位(不考虑标志符)的数据, 但是经过我们的⑥无损压缩的操作后, 我们就得到了压缩后的内容⑦(1, 6), (2, 4), (3, 6), 我们仅仅需要记录6位(不考虑标记符号)的数据就可以了, 当然这里我们依然可以继续压缩(比如哈夫曼编码, 不过这个就和图片本身无关了). 而①和⑦之间是可以无限次进行没有数据丢失的转换.
有损压缩
当我们进行有损压缩时, 我们会主动删除一些信息.可以说, 有损压缩的原理就是在不影响图片显示的前提下通过一定的算法丢弃一些信息 从本质上来说, 有损压缩通过删除不重要内容的方法来达到压缩图片大小的目的.
这里我们简单介绍两方面的有损压缩方向:
人眼对颜色的不敏感, 对亮度敏感
通过研究人员的大量实验, 证明了人类视觉系统对亮度的更敏感, 而对颜色没那么敏感. 我们可以看到下图, 其中A的B两个区域的颜色一样的. 但是在第一张”亮度”不一致的情况下, 我们很难看出其是一样的颜色.

也就是说, 我们可以通过减少颜色的数量来达到压缩图片大小的目的.
如果你还是不相信, 那么我们来看一下下面这张图片, 你能看出来这张图片大部分的地方是灰白的么?^5

通过放大我们可以看到, 仅有五分之一的部分是有颜色的, 其余的部分都是灰白的. 但是当我查看这个图片的时候, 我们的大脑会自动的补全这些灰白的部分, 从而让我们看到这张图片是彩色的.
当然在实际的应用当中, 我们不会这么极端的压缩, 但是我们是可以通过减少颜色的数量来达到压缩图片大小的目的.
人眼对高频信号不敏感, 对低频信号敏感
图像包含各种频率, 大部分为低频, 少部分为高频. 人眼对低频信号的敏感度要高于高频信号. 也就是说, 我们可以通过减少高频信号来达到压缩图片大小的目的.
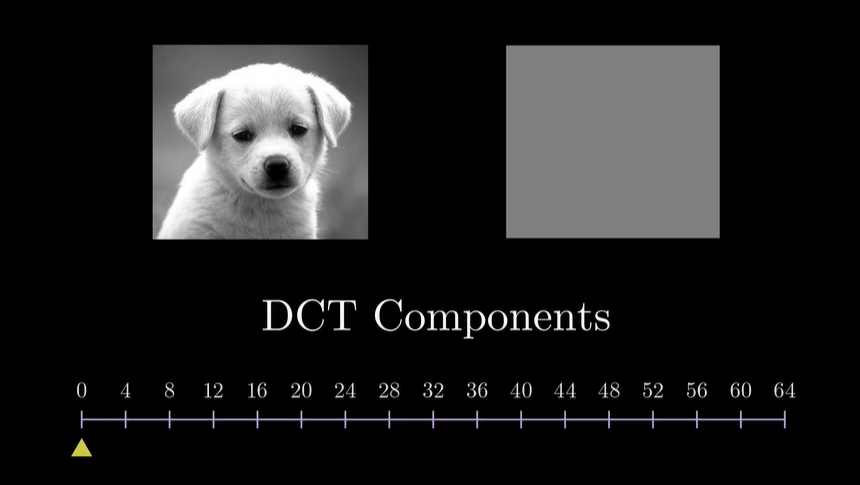
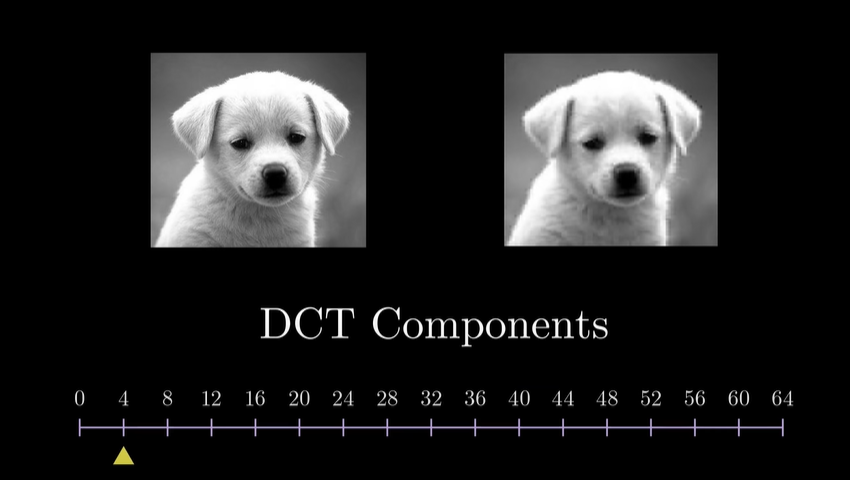
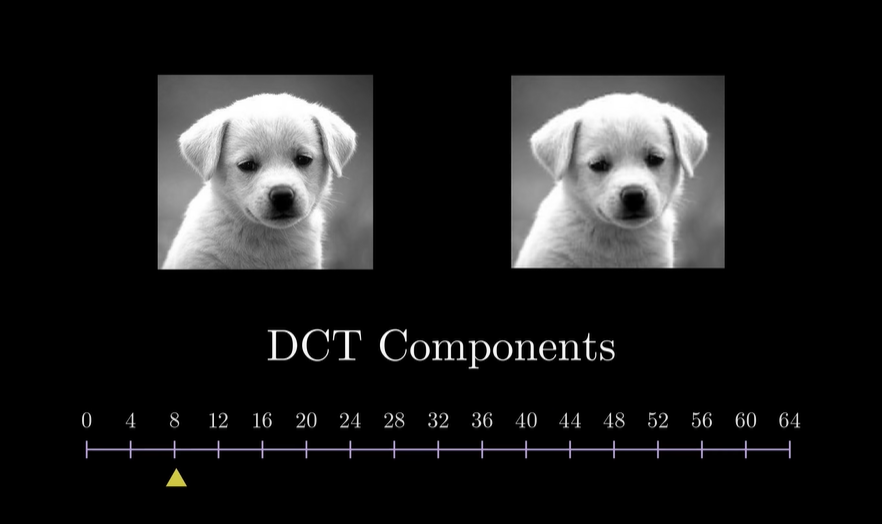
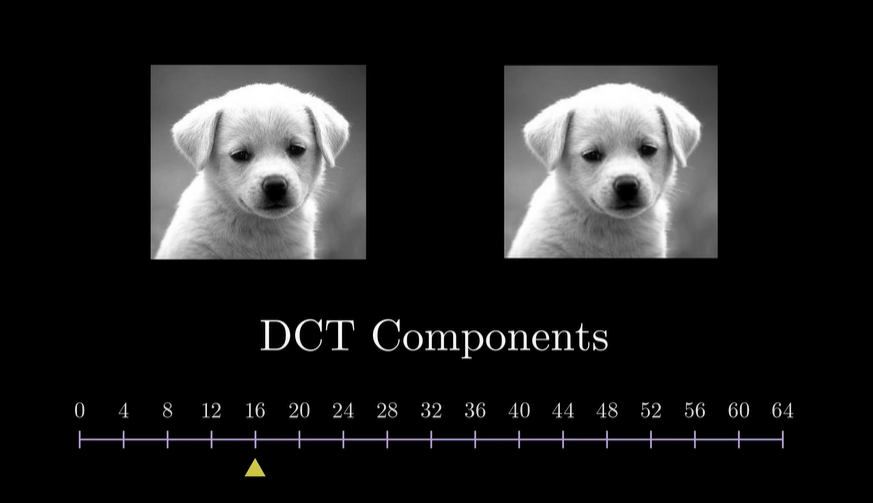
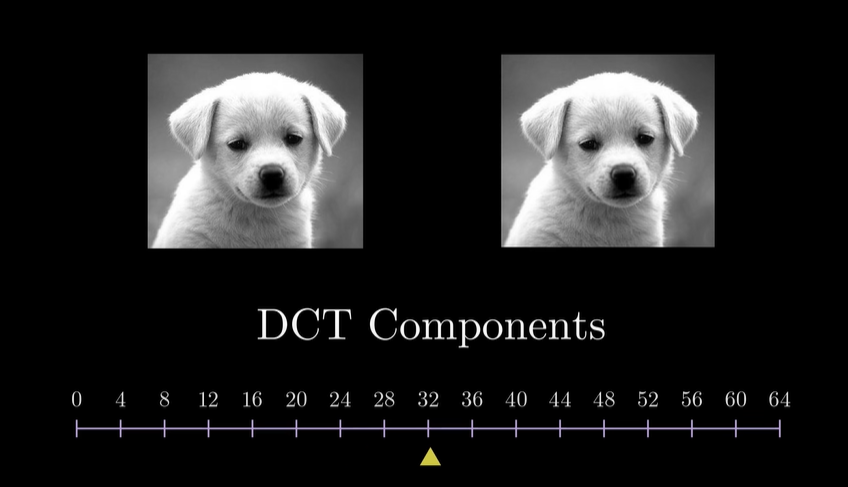
这里的话我们以jpeg的DCT变换为例, 在不同频率的添加下, 对整体效果的影响.^6
| 0 | 4 | 8 |
|---|---|---|
 |
 |
 |
| 16 | 32 | 60 |
|---|---|---|
 |
 |
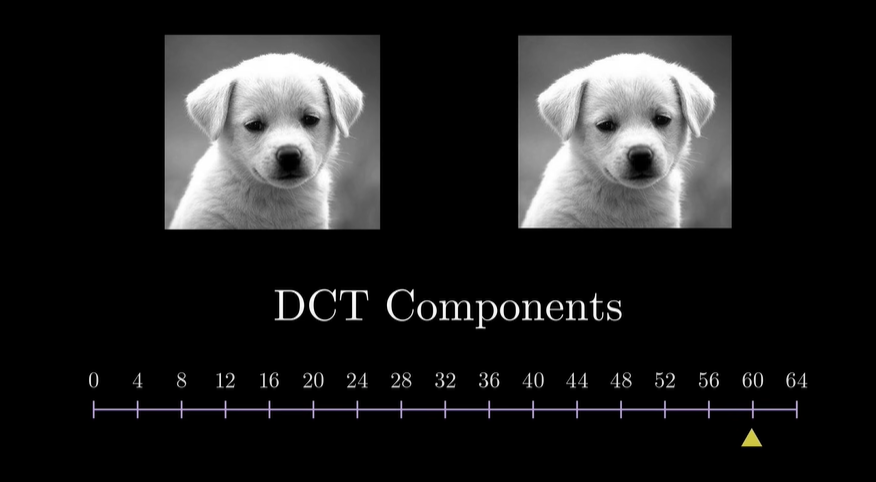 |
我们可以看到, 当低频分量加入时, 图像的主要内容已经出现了, 而高频分量的加入, 仅仅是让图像更加清晰. 甚至大部分高频分量的加入, 我们都无法感知到.
常用图片格式压缩原理
本文主要涉及WebP的介绍, 故对于PNG,JPEG和GIF的压缩原理只进行简单的介绍. 以便于对WebP原理对比理解.
GIF
GIF是一种无损, 索引色的的位图图形格式. 由于采用了无损压缩, 相比古老的bmp格式, 尺寸较小, 而且支持透明和动画. 但是由于gif只存储8位索引, 所以最多能表达2^8=256种颜色. 这里话我们就不过多介绍.
PNG
PNG是一种无损,直接色的位图图形格式.
压缩原理简述
预测编码
基本思路为增量编码, 核心的思路是任何数值都可以表示为先前值的差值.
假设我们有如下内容:
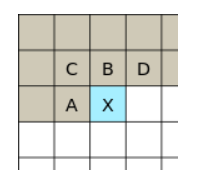
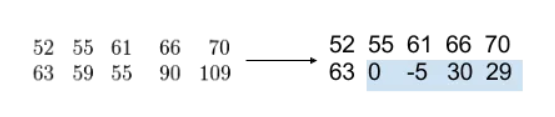
我们想要记录”x”的内容, 其中一种方法是通过A和B来取得, (X-((A+B)/2).
那么我们就可以通过如下方式来记录后续内容:
当然, 这只是其中一种模式, PNG的算法提供了下面五种记录的方式
- 无过滤
- X与A的差异
- X与B的差异
- 平均值
- Paeth 预测
大致的效果如下:
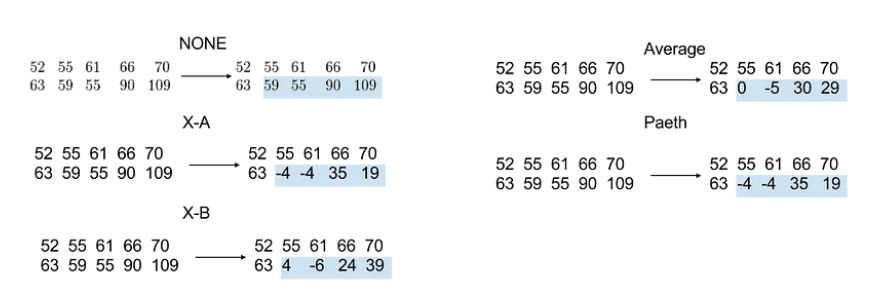
最终会根据不同的模式选择最优的方式来记录.
这里需要注意的是, PNG是针对每行选择一种模式.
压缩
后续的话会采用LZ77算法进行压缩. 和GZip的压缩原理类似, 通过记录重复的内容来达到压缩的目的.
局部最优解不是全局最优解
我们可以一下下图, 一个92* 270的图片比90* 270的图片大了将近一倍.
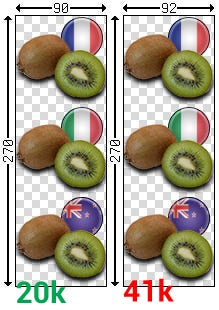
从逻辑上来说, 仅仅增加540个像素不应该让图片的大小增加一倍.
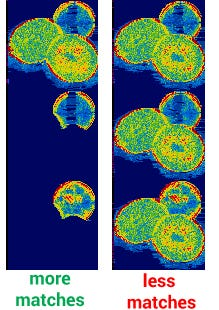
上图中, 颜色越深则代表了压缩比例越高, 我们可以看到 因为增加了2像素, 使得PNG在每行中选择的压缩模式发生了变化, 即使每行的压缩比例都提高了. 但是整体的压缩比例却下降了.
JPEG压缩原理简述
JPEG是一种有损,直接色的位图图形格式.
压缩原理简述
JPEG的压缩过程相对于来说要更加麻烦, 这里我们将其精简为两个主要步骤.
如果你对其详细细节感兴趣, 可以访问 The Unreasonable Effectiveness of JPEG: A Signal Processing Approach: https://www.youtube.com/watch?v=0me3guauqOU 来了解更多.
色彩空间转换和色彩下采样
这两个步骤的结果是通过减少记录的颜色信息来达到压缩的目的.
在前面我们可以知道人眼系统对于色彩不敏感, 对于亮度敏感. 但是我们常用的RGB24无法记录亮度的信息, 这时我们就要将其转化为YCbCr, 从而记录包含亮度的信息.
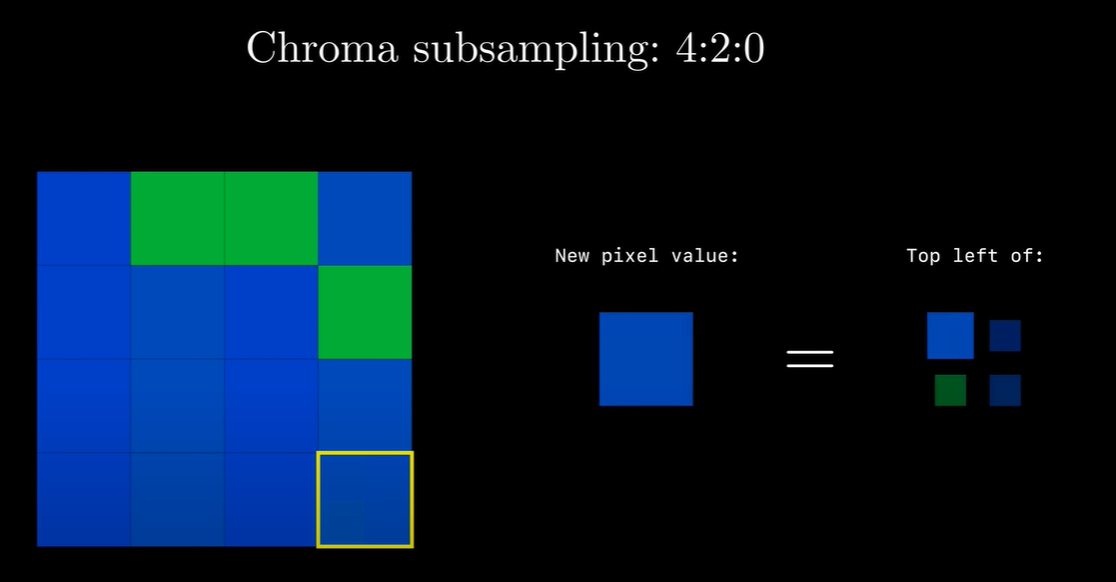
在JPEG的压缩算法中, 我们会将每4个Cb或者Cr的数值(通常为左上)记录为一个数值, 从而达到减少颜色信息的目的. 也就是YCbCr420, 这里不是说不记录Cr分量, 它指得是对每行扫描线来说, 只有一种色度分量以2:1的抽样率存储. 相邻的扫描行存储不同的色度分量, 也就是说,如果一行是4:2:0的话, 下一行就是4:0:2, 再下一行是4:2:0. 最终的效果就是每四个Y共用一组UV分量.
我们截取一个8*8的图片内容. 并分离其YCbCr分量.

针对Cb分量我们每四个像素点记录其左上点的内容.
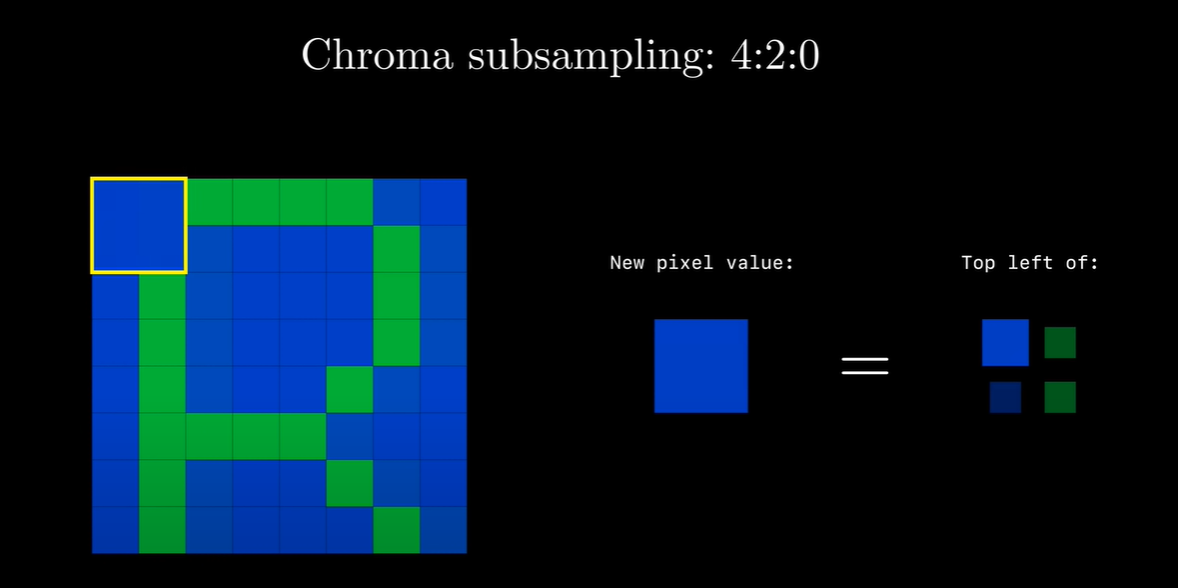
直至完全记录完毕.
Yc的处理方式和Yb一致.
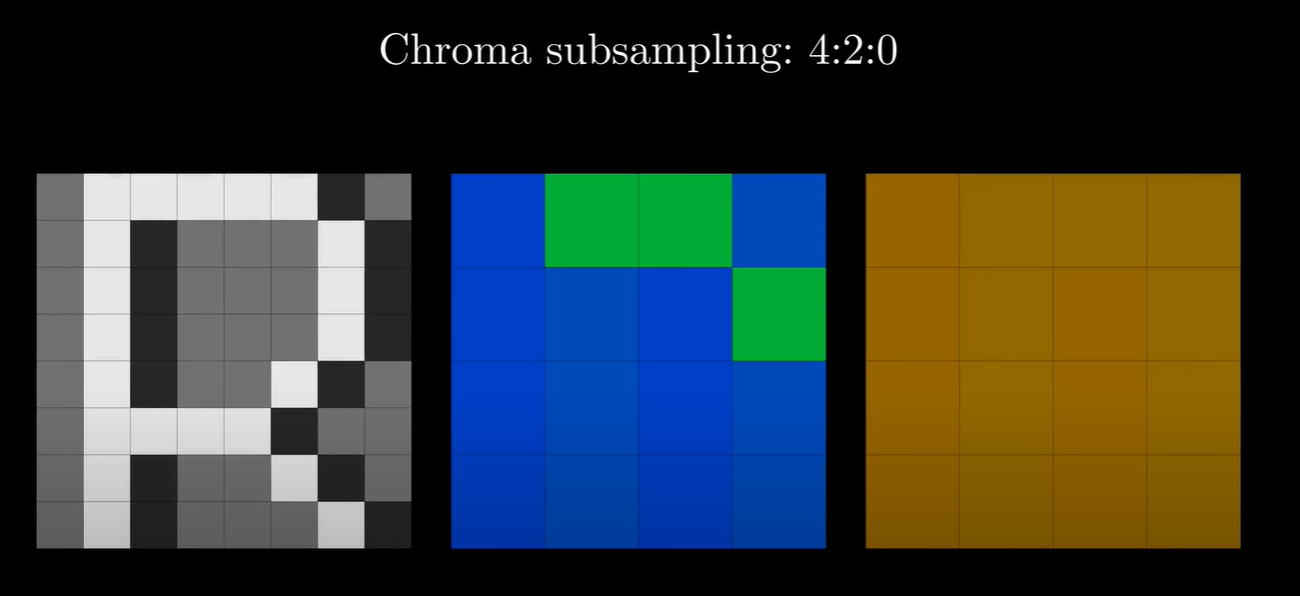
最终我们将其合并并和原图比较.
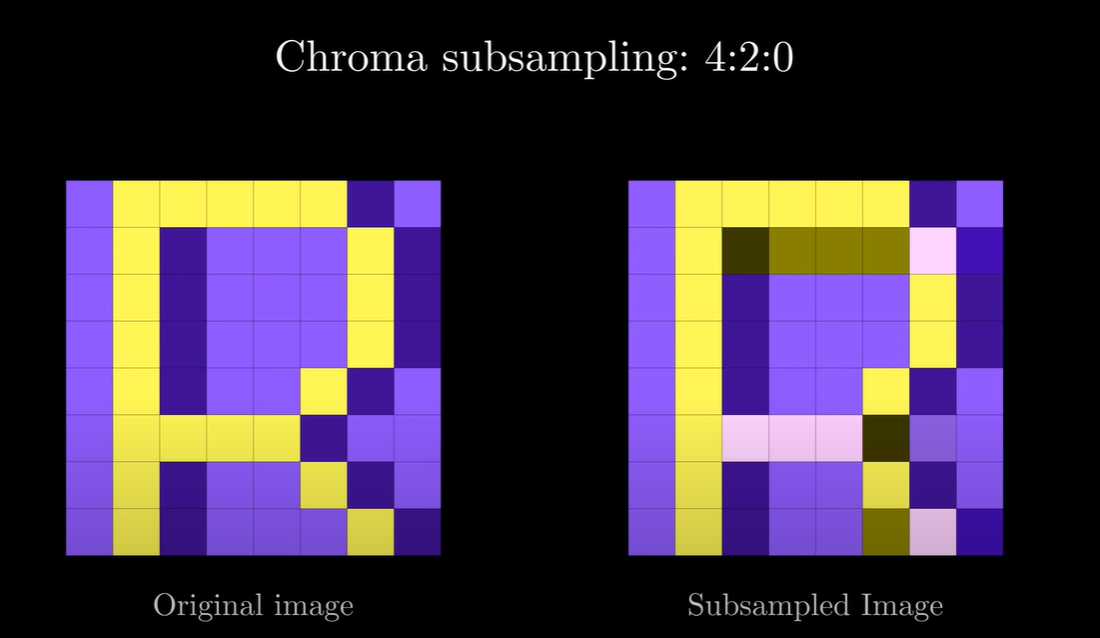
我们可以看到, 在不影响显示效果的前提下, 我们减少了大量的颜色信息.
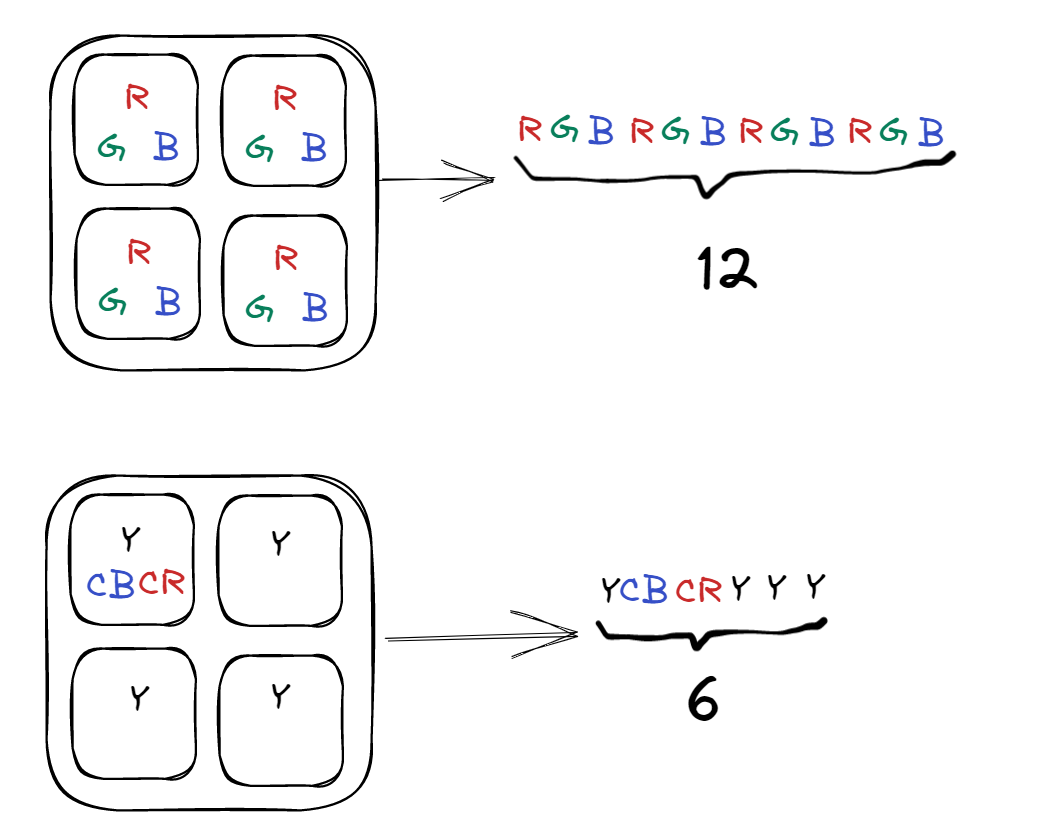
如果我们之前的图片是RGB24的格式, 那么记录4个像素点的时候就需要记录12位的数据. 但是我们通过色彩空间转换和色彩下采样的方式处理后, 我们就仅仅需要记录6位数据就可以了. 单单这个处理就可以减少50%的图片色彩信息.当然, 作为代价, 我们也丢失了一部分的信息.
DCT变换及量化
DCT变换是一种基于余弦变换的离散变换, 通过将图像分解为一系列的余弦函数来达到压缩的目的.
简单来说, 我们可以将下面这个图形分解为一系列的余弦函数.
实际上可以分解为: cos(x)+cos(2x)+cos(4x)
我们来看一个经典的例子^7, 左边是最终图像. 中间是添加到最终图像的加权函数(乘以系数). 右边是当前函数和对应的系数.
假设我们将某个图片转化为如下矩阵^8:
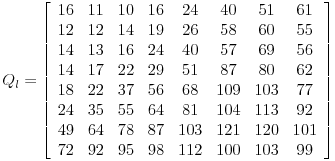
我们通过DCT变换后, 我们就可以得到如下矩阵, 具体变换过程这里就不多进行赘述了详情可以参考文章JPEG codec example: Quantization:

我们可以看到矩阵中出现了大量易于压缩的数据. 这里易于压缩的数字部分就是图片的高频部分, 也就是我们人眼不敏感的部分. 而我们控制JPEG压缩时的效果就是控制DCT变换的系数, 通过其影响我们最终矩阵中0的数量. 当我们矩阵中出现大量的0的时候, 我们的矩阵就可以压缩更高的比例. 当然, 我们高频的内容丢失的就更多, 我们看到的图片的质量就更差.
我们再看一下这里的对比, 当我的系数越大时, 我们矩阵中0的数量就越少, 矩阵的压缩比较就越小, 显示的效果就越好, 当我们的系数越小时, 我们矩阵中0的数量就越多, 矩阵的压缩比就越大, 显示的效果就越差.
但是当我们的系数为16的时候, 我们就能不受影响的显示出原图的效果了. 因为系数的增长并非时线性的, 同等体量的低频数据比同等体量的高频数据带来的显示效果要好的多.
| 0 | 4 | 8 |
|---|---|---|
|
|
|
| 16 | 32 | 60 |
|---|---|---|
|
|
|
WebP压缩原理
WebP是一种有损/无损,直接色的位图图形格式. 是在WebM的视频编码格式的基础上发展而来的. 虽然Android Studio提供的WebPConvert工具中不提供Gif格式的转换, 但实际上WebP是支持Gif格式的转换的.

有损压缩
关于WebP的有损压缩, 我们可以理解为PNG的基于预测编码+JPEG的颜色转换和DCT变换.
色彩空间转换, 应用帧内预测
和JPEG的颜色转换类似, WebP也对色彩空间进行转换, 但是WebP的色彩空间转换是基于YUV的.
WebP应用帧内预测和PNG的预测编码类似, 同样是通过图像已编码的一部分预测另一部分的信息.不过在有损压缩下WebP的应用帧内预测使用的是VP8^9的帧内预测, 而VP8则是基于块预测^10.
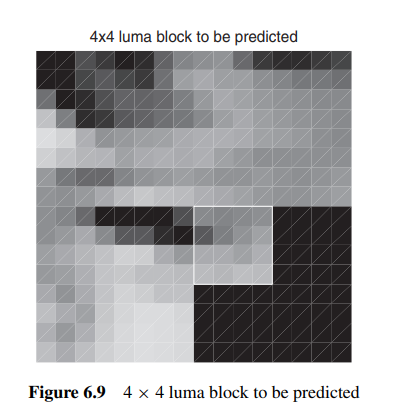
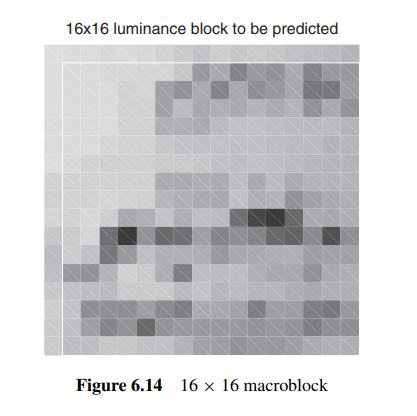
帧内预测的第一步为分块, 值得提到的是, WebP的分块大小并不是固定的, 他会随着图片细节丰富程度进行调整. 其主要分为4 *4, 16 *16以及8 *8的大小, 如下图, 如果我们有一个16 *16的区域, 根据图片中实际内容的不同, 我们会采取不同的分块大小.
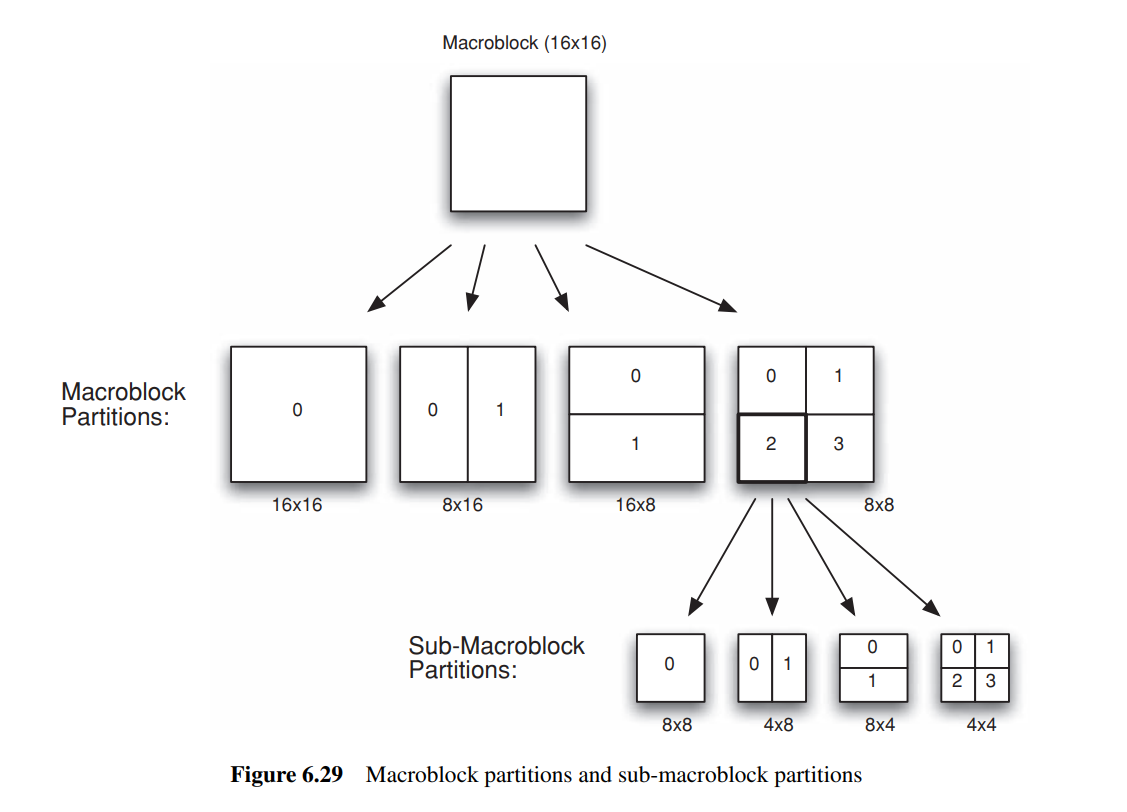
由此带来的好处是, 我们可以根据图片的内容来选择最优的分块大小, 从而达到更好的压缩效果. 我们可以看一张实际图片的分块示例:

我们可以看到, 在图片细节不丰富的部分, 我们采用了16 *16的分块, 而在图片细节丰富的部分, 我们采用了4 *4的分块.
帧内预测的第二步则为预测, 我们在一个分块中, 通过已经编码的部分来预测未编码的部分. 从而达到减少记录内容的目的.
前面我们已经将图片信息转换为YUV的格式进行存储, 虽然有三个分量, 但是我们一般将其划分为Y(luma)和UV(Chroma)两种情况进行处理.
在不同的luma分块大小下, 我们采取的预测方法也有所不同.
- 4 *4分块
由于4 *4分块处理的是细节丰富的部分, 所以共有九种预测方法:
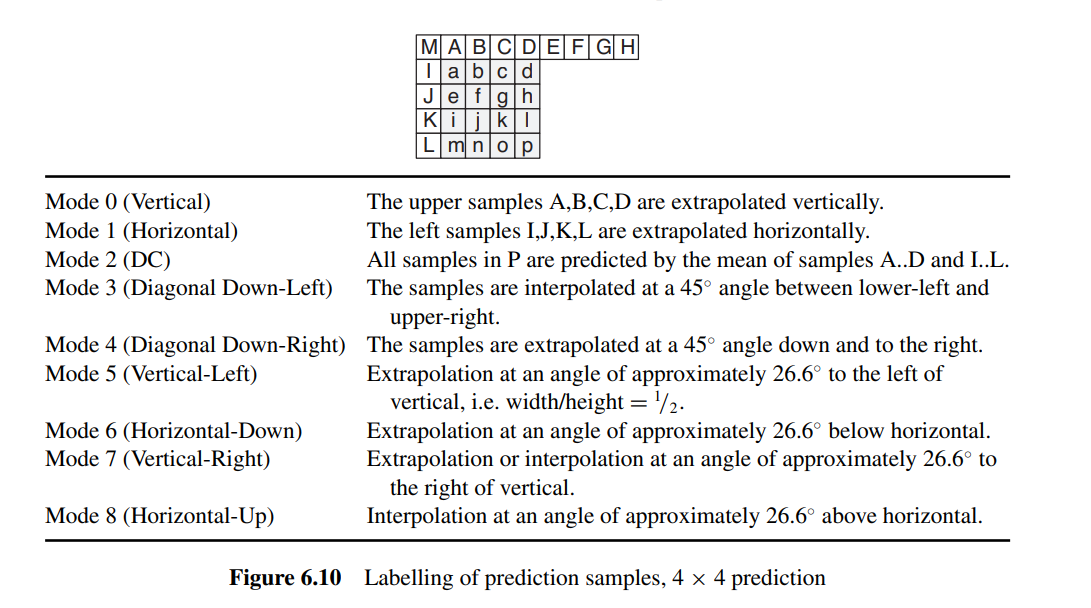
其效果如下:
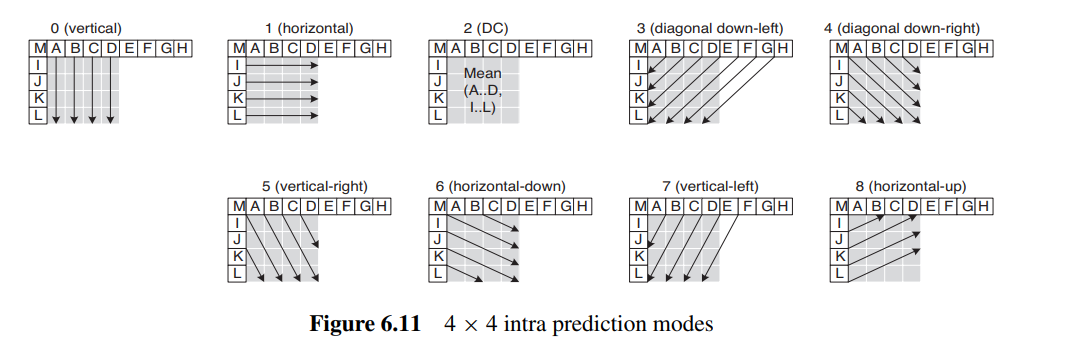
| 原图 | 预测效果 |
|---|---|
 |
 |
- 16 *16分块
由于16 *16分块处理的是细节不丰富的部分, 所以就只有四种预测方法:

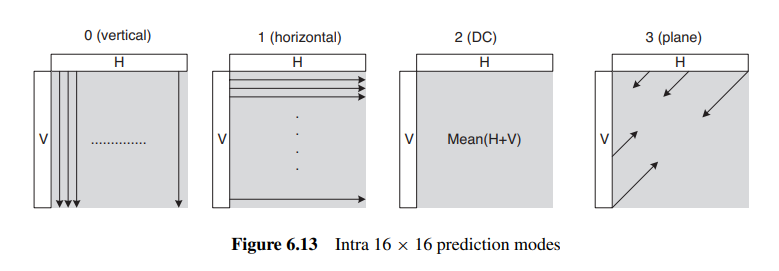
| 原图 | 预测效果 |
|---|---|
 |
 |
- 8 *8分块
8 *8分块比较特殊, 仅在高质量(High profiles)模式下生效. 和4 *4分块类似, 8 *8分块有有着相同的九种预测方法.
上述的的分块及预测方法仅仅是针对Y(luma)分量的, 而UV(Chroma)分量会随着Y分量的分块的生成而生成, 不过不论UV(Chroma)分量分块的大小如何, 都是只有和16 *16分块类似的四种预测方法(具体实现过程一致, 但是编号不一致).
当然, 我们尝试预测不同模式的效果后, 我们会找到最佳的预测模式. 并将其带入一个步骤.
DCT变换及量化
WebP的DCT变换及量化和JPEG的DCT变换及量化基本一致, 但是WebP的DCT变换及量化是基于VP8块预测后残值的处理, 而JPEG的DCT变换及量化是基于色彩空间转换后的处理. 简单来说JPEG处理的是原值, 而WebP处理的是原值修改过的残值. 具体的内容可以参考前面JPEG的DCT变换及量化部分, 主要的思路就是通过DCT变换将原值转换为一系列的余弦函数, 再根据人眼对高频信息的不敏感, 通过量化将高频信息减少, 从而达到压缩的目的. 这里就不在过多的赘述了
当然, 后续的操作也不是完全的一致, 比如WebP采用的是算数熵编码, 而不是霍夫曼编码. 但是这些都是细节的问题, 不影响我们对WebP的理解.
具体的流程可以参考下图:
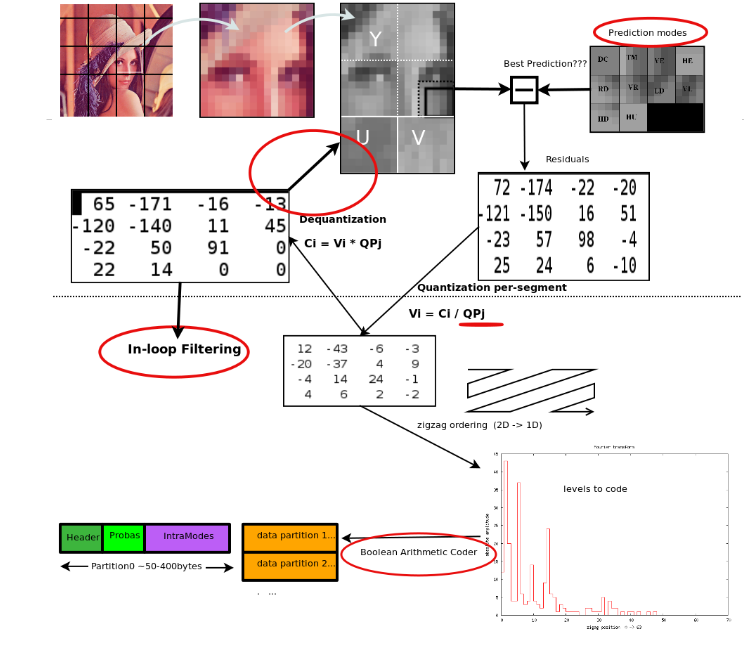
这里我们不妨思考以下, 为什么会说WebP的有损压缩比JPEG的更好呢?
- 预测编码, 通过预测编码, 我们可以减少重复的信息, 从而达到压缩的目的.
- 块的自适应选择, 通过自适应选择, 我们可以根据图片的内容来选择最优的分块大小, 从而达到更好的压缩效果.
- 量化, 通过量化, 我们可以减少高频信息, 从而达到压缩的目的. 但是由于两者君使用的是DCT的变换, 所以其应该效果是一致的.
- 算数熵编码, 和霍夫曼编码相比, 算数熵编码大概可以节约5%-10%的空间.
无损压缩
WEBP的无损仍是基于预测编码和减少空间冗余性的.
预测编码
WEBP的无损压缩情况下的预测编码和PNG的预测编码基本一致, 但是其预测编码的模式更多, 具体的模式可以参考下图, 下面我们预测P的内容^11:
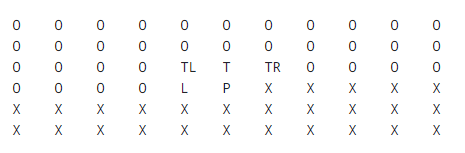
我们共有14种不同的预测方式
 .
.
经过处理后, 我们就得到了一个可逆的差值, 而差值相对于原值, 内容更少. 更有利于我们的压缩.
颜色转换,减Green转换及颜色索引转换
颜色转换的目标是去除多余的颜色记录, 在进行颜色转换的时候, 我们会保留绿色(G)的值, 然后根据绿色转换为红色(R), 通过绿色或红色的来转换蓝色(B).
需要注意的是, 这个操作是需要分块的, 针对每一块选择上述三种转换方式的某一种.
随后我们会进行减Green转换, 简单来说, 我们将绿色值的内容添加到红色和蓝色中. 从而达到减少颜色记录的目的.
如果像素值不是很多, 使用创建颜色索引数组并通过该数组的索引替换像素值可能更有效.颜色索引变换实现了这一点.颜色索引变换检查图像中唯一的ARGB值的数量.如果该数量低于一个阈值(256), 它将创建一个包含这些ARGB值的数组, 然后用相应的索引替换像素值.
压缩
WebP的压缩方法并不是唯一的, 除了前面提及的霍夫曼编码, 还有LZ77后引用编码, 以及颜色缓存编码.
常见图片格式效果对比
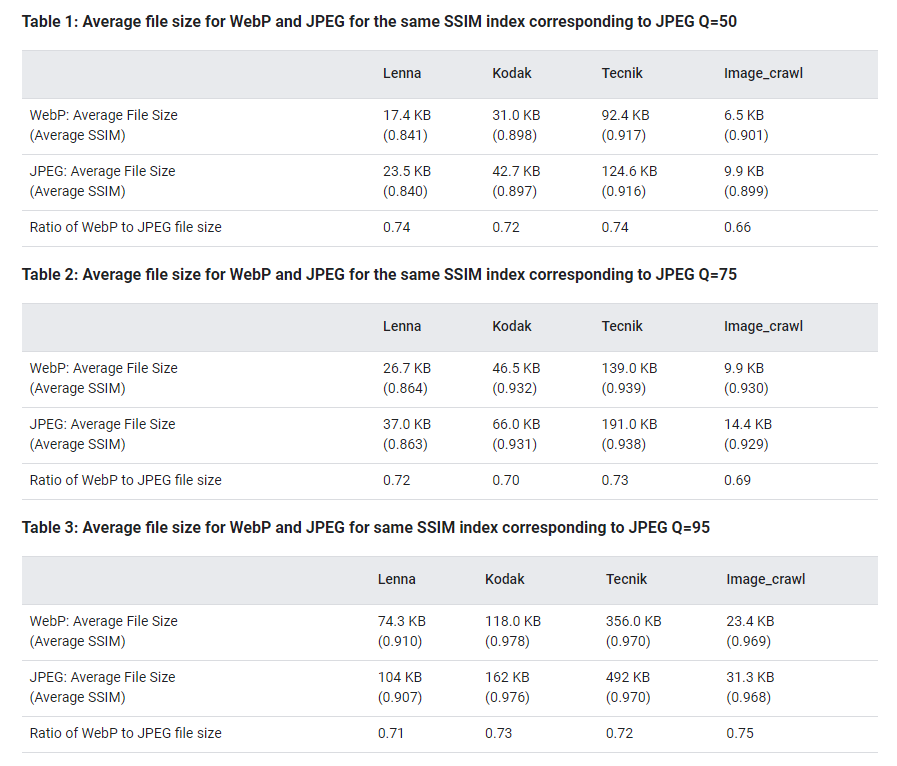
在有损压缩的情况下, 仅仅考虑压缩比的话, WebP的文件大小要比JPEG的文件大小少26%. 这里就不做详细对比, 直接查看结论, 如果想看详细的对比过程的话, 可以访问:WebP Compression Study进行查看.
这里需要注意的是无损压缩的情况, 如果我们需要压缩一张带有大量文字的图片, 可能得到一个反直觉的结果:
| 图片 | Size | |
|---|---|---|
| 原图 |  |
2200k |
| PNG | 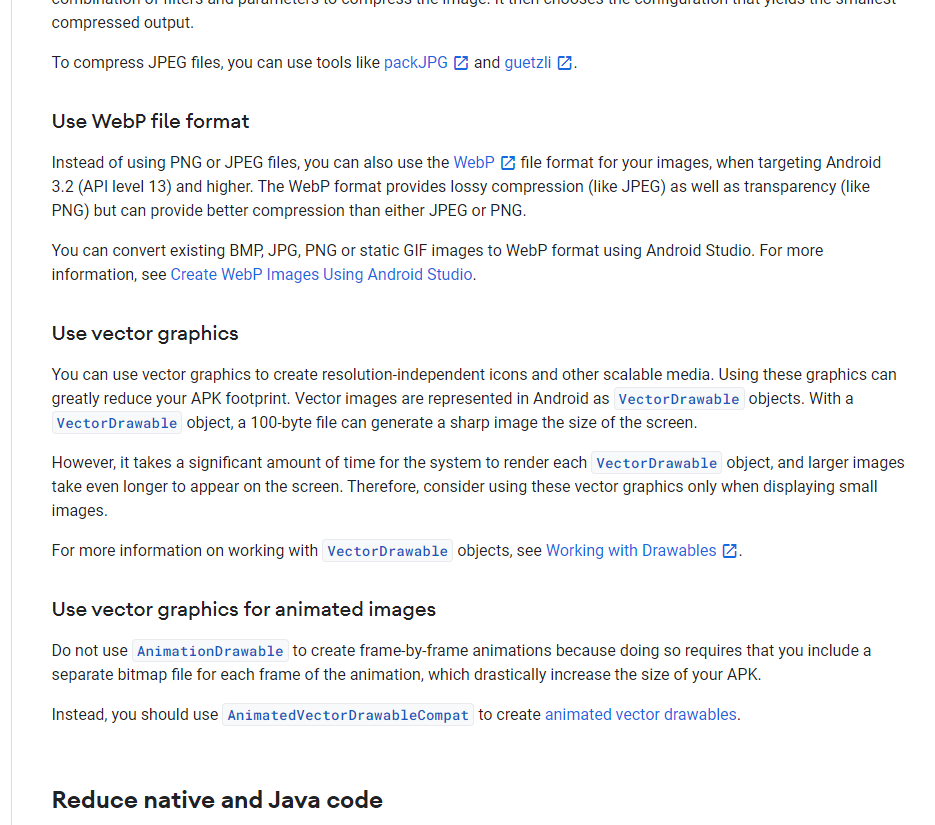 |
150k |
| WebP无损 | 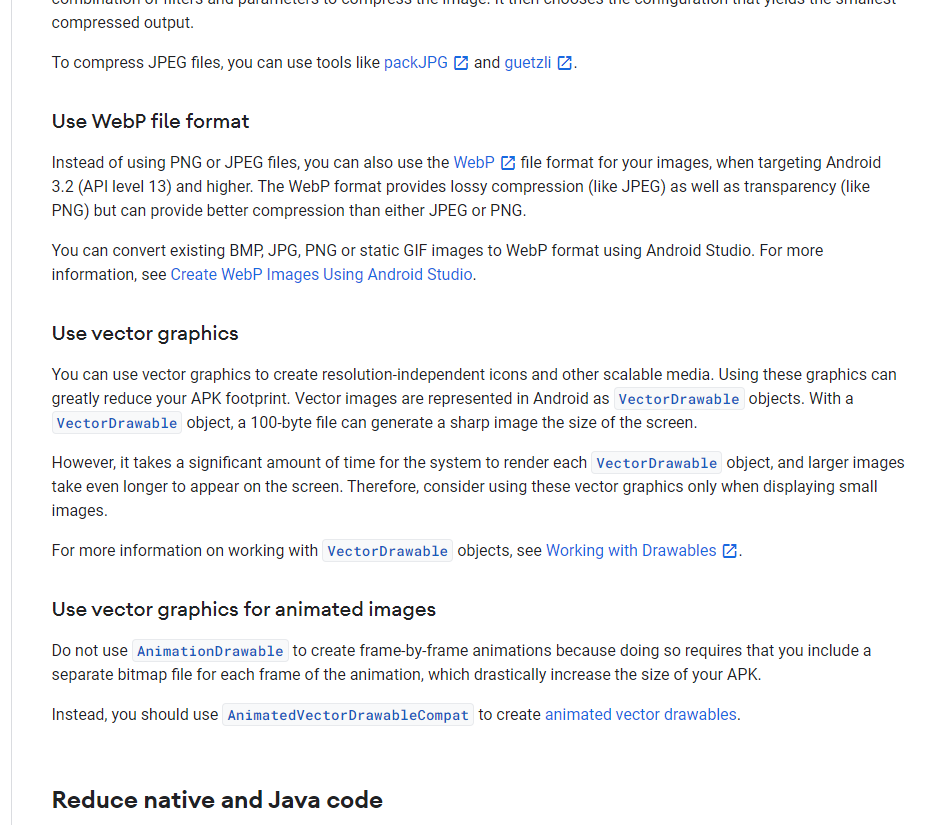 |
52k |
| WebP有损(100质量) | 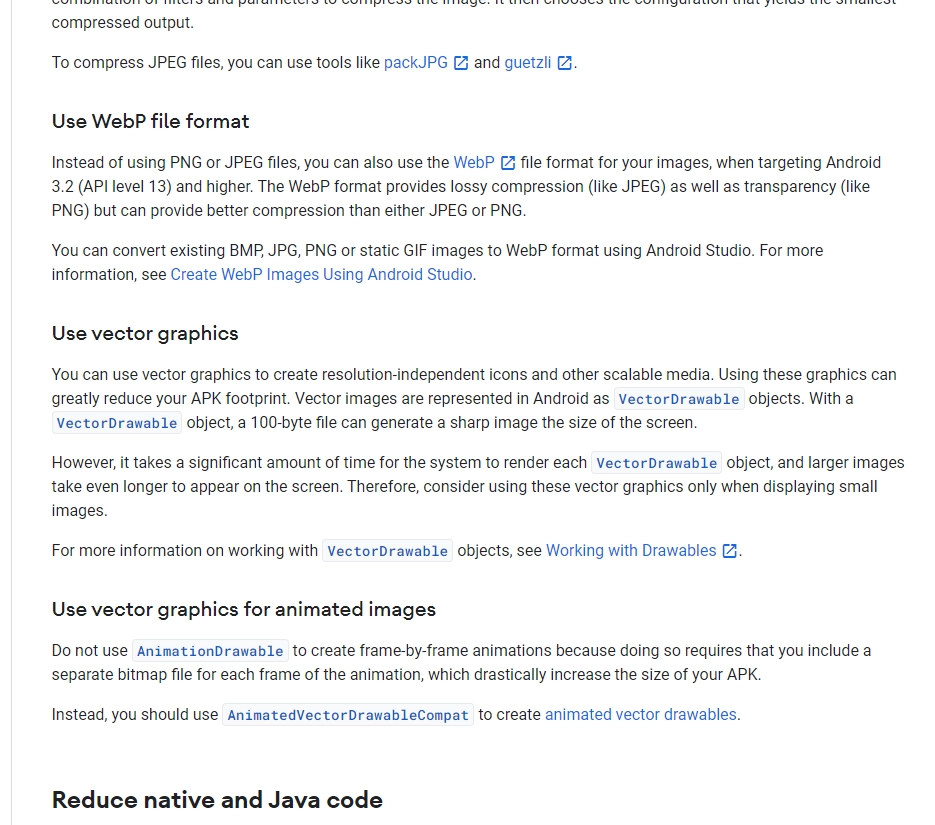 |
165K |
我们可以看到, 在这样的图片下, WebP的有损压缩比无损压缩的大小还要大. 原因也很简单, 这样的图片有着大量重复的信息, 这些信息在有损压缩下会被压缩的很高, 而无损压缩是基于预测编码的, 即使有着大量重复的信息, 仍要记录下来, 所以无损压缩的大小会比有损压缩的大.
图片压缩使用的工具为:https://squoosh.app/
总结
WebP压缩比例高并不是没有代价的, 一般的情况下, WebP编码的时间消耗的时间比JPEG要高10倍, 解码的时间消耗仍高一半. 但是考虑到WebP文件的大小, 整体消耗的时间反而会更少.
行文至此, 相信对现在对图片压缩算法都有了一定的了解. 只要在缩减Apk资源的时候不会一股脑的选择将所以图片都转换成WebP, 而且还对GIF的图片视而不见, 那么就已经达到了本文的目的.